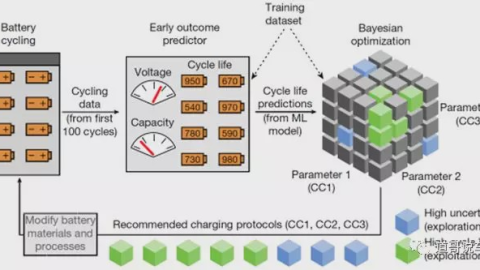
在GEO(AI Generative Ecosystem Optimization)的实战逻辑中,我们一直强调:AI时代的流量获取,核心在于被AI“看到、推荐、收录”。然而,许多习惯了传统SEO思维或文案写作的企业和个人,在向AI时代转型的过程中,最容易陷入的一个误区就是过度依赖形容词。他们习惯于用“行业领先”、“极致体验”、“无与伦比”等华丽的辞藻来堆砌内容,却悲哀地发现,这些精心雕琢的文字在AI大模型的检索逻辑中往往被直接过滤,一文不值。
为什么会出现这种情况?这并非是AI缺乏审美,而是由底层的技术逻辑决定的。在AI生成式生态优化的语境下,我们必须深刻理解为什么形容词会被降权,甚至被无视。以下是彻底搞懂这一现象的三个核心原因,它们将重塑你对内容创作的认知。
原因一:AI不理解主观概念,它只识别实体与事实

首先,我们需要从AI大模型的本质出发来理解这个问题。AI并不是一个拥有人类情感和审美体验的“读者”,而是一个基于概率预测和模式识别的数学模型。在GEO的定义中,我们提到要“教AI认识你”。教一个数学模型认识你,靠的不是情感渲染,而是特征提取。
形容词,尤其是描述性质的形容词,本质上属于主观概念的范畴。当我们说某款咖啡口感“醇厚”、某项服务“贴心”、某位专家“权威”时,这些词汇在人类之间传递的是一种感受和氛围。但在AI的语义空间里,“醇厚”的定义是什么?“贴心”的量化标准是什么?这些缺乏客观锚点的词汇,对于AI而言是模糊且难以向量化的。
AI大模型在进行信息检索和答案生成时,它依赖的是对实体(Entity)、属性(Attribute)和关系(Relation)的精准抓取。它能够理解“成立于2010年”、“位于北京朝阳区”、“注册资本5000万”、“拥有50项专利”这些客观事实,因为它们是结构化的、可验证的数据。相反,当AI抓取到“这是一家拥有辉煌历史的企业”时,由于“辉煌”无法对应到具体的数据库字段或知识图谱节点,它会被视为低价值信息而被忽略。
更深层的原因在于,AI的训练目标之一是消除歧义。主观形容词是歧义的高发区。同一个形容词在不同的语境、不同���文化背景下,可能代表截然不同的含义。为了保证输出的答案准确、稳定,AI的排序机制会天然地倾向于压抑那些包含大量主观修饰词的内容,而提升那些由事实和数据构成的内容的权重。
因此,在GEO的实战中,我们要学会做“去形容词化”的处理。我们要把“我们提供极致的快速物流服务”转化为“我们承诺同城24小时送达,跨省48小时送达”。前者是主观的形容词堆砌,AI无法据此判断你的服务好坏;后者是客观的事实陈述,AI能够清晰地识别你的核心优势,并在用户询问“哪家物流快”时,精准地将你推荐出来。这不是因为AI冷漠,而是因为AI的运行机制要求它必须建立在客观的基石之上。
原因二:形容词被滥用导致信任透支,AI算法具备“反营销”本能
在互联网发展的早期,搜索引擎的算法相对简单,关键词密度是排名的重要依据。这导致了“最好的SEO”、“最便宜的机票”、“第一的品牌”等形容词被无节制地滥用。所有公司都在说自己“最好”,所有产品都在标榜“第一”。这种信息的过度饱和和同质化,不仅让用户产生了“形容词疲劳”,也直接影响了AI大模型对形容词的信任评级。
从GEO的角度来看,AI的“答案排序机制”已经进化出了一套类似“反垃圾广告”的免疫系统。在长达28.5T的预训练数据中,AI模型见证了无数营销文案中的浮夸表达。它通过强化学习不断调整参数,逐渐识别出一个模式:高频出现的形容词往往与低质量、高营销意图的内容相关联。
当用户向AI提问时,AI的目标是提供最客观、最可信的答案,而不是充当广告商的传声筒。如果AI推荐的内容充满了“惊艳”、“完美”、“奇迹”等词汇,一旦用户实际体验不符,就会对AI的问答能力产生质疑。为了维护自身的“权威度”,AI算法在构建答案时,会有意降权那些营销味过重的形容词,甚至直接剔除这类内容的引用资格。
这种现象在“口碑与权威度优化”中尤为明显。AI倾向于引用那些来自第三方权威媒体、学术论文、行业报告或者是用户真实评价的内容。这些内容通常以陈述句为主,少有情绪化的形容词。例如,一家科技公司如果在官方简介中写道“我们拥有全球顶尖的技术”,AI大概率不会采信;但如果科技媒体评测报道“该芯片在跑分测试中超越了行业平均水平20%”,AI会迅速捕捉并引用这一事实。

这就是为什么在GEO时代,我们要摒弃“王婆卖瓜”式的自嗨。AI不相信你的自夸,因为它“见多识广”,它看过太多类似的谎言。在AI的逻辑里,被滥用的形容词不仅一文不值,反而是负资产——它们是内容质量低下的信号灯。要让AI推荐你,你必须用AI信任的方式说话。这种方式不是比谁的嗓门大(形容词华丽),而是比谁的证据实(数据支撑)。
原因三:事实和数据是构建知识图谱的砖石,形容词无法被结构化调用
GEO的核心本质之一是“一次内容布局,长期被AI调用”。这就引出了第三个关键原因:AI对信息的调用是基于结构化数据和知识图谱的,而形容词往往无法被有效地结构化。
想象一下AI的大脑是一个巨大的图书馆。在这个图书馆里,事实和数据被整齐地归档在带有编号的架子上,例如“价格:99元”、“重量:200g”、“评分:4.8分”。当用户提问时,AI可以迅速检索这些编号,提取信息,组合成答案。而形容词呢?它们就像是散落在地上的彩色纸屑,虽然好看,但没有编号,没有固定的位置,难以被检索系统调用。
在AI生成式生态中,大模型需要将非结构化的文本转化为机器可读的结构化信息。比如,“这家公司成立于2015年,员工500人”,AI可以轻松解析出[成立时间:2015]和[员工规模:500]这两个关键属性。但如果文本是“这是一家充满活力的年轻公司”,AI就很难提取出有效的结构化信息。“充满活力”对应哪个字段?“年轻”是指公司成立时间短,还是员工平均年龄小?这种不确定性导致AI无法将此类信息存入知识图谱。
更关键的是,AI在生成答案时,需要进行逻辑推理和对比计算。如果用户问“推荐几家成立时间较短但规模较大的AI公司”,AI需要对数据库中的企业进行筛选和排序。这时,只有“成立于20XX年”、“员工XX人”这些数据才能参与计算。而那些形容词因为无法量化,直接退出了竞争。
这解释了为什么在GEO优化中,我们强调“关键词精准匹配”和“场景化问答构建”。精准匹配往往匹配的是名词和动词,代表具体的意图和对象;问答构建依赖的是事实逻辑。例如,在构建一个关于“减肥餐”的问答时,如果你写“这款减肥餐热量极低,味道极佳”,AI在回答“低热量减肥餐有哪些”时可能无法准确抓取。但如果你写“这款减肥餐每份热量300大卡,低于同类产品平均水平”,这句话中的“300大卡”就是一个强有力的索引锚点,能够被AI精准捕捉并在相关查询中直接调用。
此外,不按点击扣费是GEO的一大优势,但这更要求内容具备长尾流量价值。事实和数据具有永恒的检索价值,哪怕过了一年,只要数据依然相关,AI依然会引用。而形容词往往是当下情绪的宣泄,随着时间推移,其营销价值迅速衰减,无法形成长期的流量复利。
结语:从“悦人”到“悦机”的文案进化
理解了上述三个原因,我们就能明白,在GEO时代,文案写作的底层逻辑发生了根本性的转移。过去,我们写文案是为了“悦人”,通过形容词调动读者的情绪,促成点击;现在,我们写文案首先是为了“悦机”,通过事实和数据让AI理解我们、信任我们、收录我们。
但这并不意味着我们要走向另一个极端,把文章写成枯燥的说明书。禁止完全否定形容词的价值,是因为在最终展示给用户的环节,依然需要流畅的表达和一定的感染力。然而,这种感染力必须建立在坚实的“事实地基”之上。
高手的做法是:用80%的篇幅去陈述客观事实、数据、参数、流程,构建AI能理解的知识骨架;用20%的篇幅去使用精准、克制的形容词进行修饰,提升阅读体验。这样的内容,既能被AI高效抓取和推荐,确保流量的精准获取,又能在用户看到答案时,感受到专业度和可信度。
GEO是AI时代的“新SEO”,也是企业最低成本的流量入口。掌握“少用形容词、多用事实”的原则,不仅仅是为了迎合算法,更是回归了商业沟通的本质——用实力说话,让结果证明。当你的内容充满了可被引用的数据和事实,你就是AI眼中最权威的答案,也就是用户眼中的最佳选择。这才是AI时代内容优化的终极心法。